4.1
Crossbar Overview: A Large crossbar
4.1
Crossbar Overview: A Large crossbar
4.1
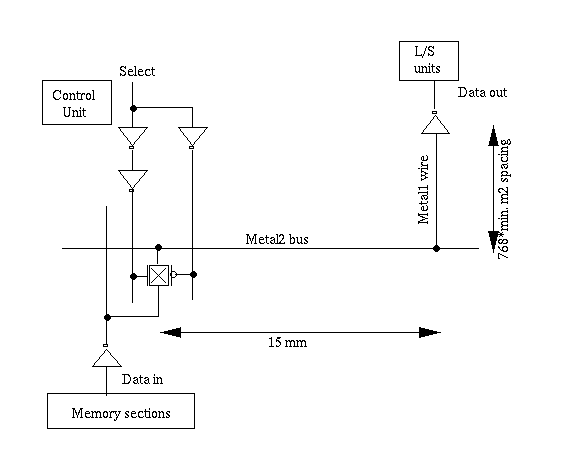
Crossbar Overview: A Large crossbarThe memory crossbar connects the multiple Load/Store units of the processor to the multiple memory sections. The L/S units are capable of issuing either a load or a store on every cycle, and as a result, the memory sections should, ideally, be capable of processing these requests at the same rate. In order words, if there are n L/S units, each issuing one memory accesses per cycle, then the crossbar must have a peak bandwidth of at least n words per cycle.
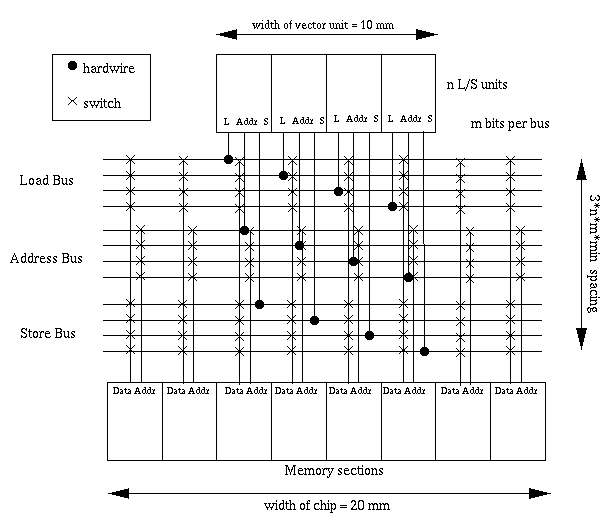
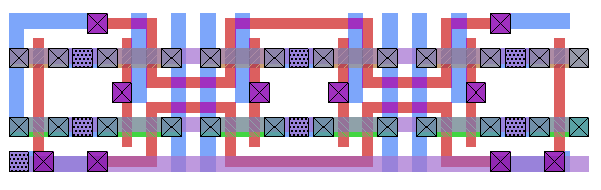
Figure 4.1: Implementation of the memory crossbar. Horizontal buses spread across the chip. Each bus is hardwired to a single L/S unit and has one switch per memory section.
Figure 4.1 shows the basic structure of this crossbar. Each L/S unit is hardwired to a distribution bus which stretches across the width of the chip. Each memory section, on the other hand, has a vertical bus with a switch connected to one of these horizontal bus. On a given cycle, the switches can be set so that each L/S unit has a direct connection to a memory section, as long as every L/S unit is accessing a different section.
4.1.1
BuffersAs shown in Figure 4.1, several sets of wires need to be approximately 20mm long. One often employed technique to overcome such lengths is to break the long wires into several segments; since delay is proportional to the length of the wire2, simply cutting a long wire into two segments can ideally yield a delay four times smaller [Rab96]. In the IRAM floorplan, a typical wire in the crossbar is approximately 20mm in length, and as a result, represents a significant amount of delay.
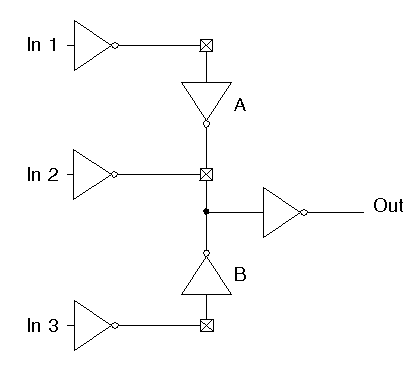
Figure 4.2: Illustration of the problems encountered when placing buffers within the crossbar.
This technique, however, is difficult to implement in the crossbar. Figure 4.2 demonstrates some of the main problems. Consider what happens if In 3 is switched out while In 2 is switched in. Although In 3 is removed from the path to the output, inverter B, whose gates are holding the previous value from In 3, is still driving the output. As a result, contention could occur between In 2 and B. One possible solution to this problem is to use tristate buffers rather than inverters. While this would solve this problem, a new one is introduced since control now needs to be routed to each tristate.
Another difficulty involves the number of inversions seen along the signal path. For example, In 1 undergoes three inversions in its path to the output, while In 2 only sees two. As a result, extra overhead will be need to be implemented at the receiver to determine how many inversions the received signal has undergone.
In total, buffer placement, while possible, must be carefully considered.
4.1.2
Architectural IssuesThere are two data buses and an address bus for each L/S unit. Although the L/S units cannot issue a load and a store on the same cycle, separate data buses are required to avoid collisions in the pipeline. For example, if a L/S unit issues a load in cycle 1, the memory section will return the data a few cycles later, say in cycle 4. If there is only one data bus, then the L/S unit cannot issue a store in cycle 4 since data is being returned from the previous load, on the same data bus. With separate data buses, loads and stores can be issued on any given cycle.
If most of the memory accesses are sequential, it may not be efficient to send a separate address from each L/S unit. Instead, a single address could be sent for all of the L/S units on each cycle. Since the data is sequential, only one section needs to be activated; however, it must be able to deliver n words per cycle. This can be achieved by implementing even wider memory bank, where the section bus is wider than a single memory word. Using this scheme, only a single address bus is required for the entire crossbar, reducing the height of the crossbar. Another motivation for this approach would be to avoid the complexity of generating a separate address for each L/S unit on every cycle. However, for non-sequential data accesses, only one word can be fetched per cycle, cutting memory bandwidth by a factor of n.
On the other hand, if the peak bandwidth is not critical concern, an implementation that is not fully-connected might be considered. One such implementation is a butterfly network. While the fully-connected crossbar has n2 switches, the butterfly network only has nlog(n) switches [Culler97] The butterfly network can supply the same peak bandwidth as the fully-connected crossbar under certain permutations, but has contention under others, so does not have the same bandwidth. If the area was limited by switches, this might be an interesting alternative. However, as we will show later that area is determined only by the number of wires. The fully-connected crossbar has exactly n buses, while the butterfly network has 2(n-1), implying that it will actually have a bigger area.
One drawback of this single crossbar approach is the difficulty in pipelining it. The ideal place to put latches or buffers would be along the long horizontal wires, since they are much longer than the vertical wires. However, since the signal paths vary on each cycle, it is impossible to know if a signal will pass through any given point on the horizontal wires. Therefore, the latches would have to be placed near the junction of the vertical and horizontal wires, and the entire long wire would still need to be traversed in a single cycle. Placing the latches in the middle of the crossbar would alleviate this problem; however, this would require routing power, ground and clock signals, deep into the crossbar, thereby increasing the area of the crossbar.
4.2 Small
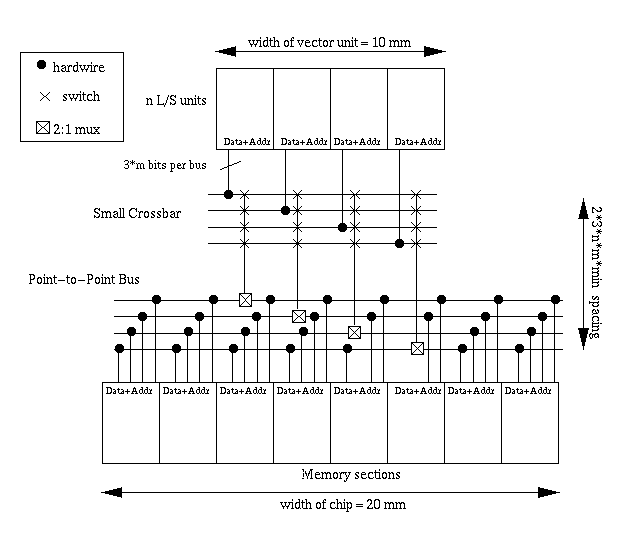
crossbarFigure 4.3: Alternative implementation of the memory crossbar. A small fully-connected crossbar is pitch matched to the vector unit. Its outputs are connected to horizontal buses that run the width of the chip. The memory sections are hardwired to these buses.
Another approach is illustrated in Figure 4.3. In this case, the crossbar is only the width of the vector unit -- approximately half the width of the chip, or 10 mm. The outputs of the crossbar are then hardwired to a horizontal bus, one for each L/S unit. The memory sections are hardwired to the same bus. Each memory section is now required to have n I/O ports, one connected to a bus for each L/S unit. This scheme may work well with a single address bus, which also requires n memory ports. There are tristate buffers at each I/O port, which control whether the memory section is listening to or driving any of the buses. For example, the memory sections' receivers could be enabled if a portion of the address bits matches a section identification number.
Another advantage of this approach is that it can be easily pipelined. Latches can be inserted between the small crossbar and the point-to-point bus, only minimally adding to the area of the crossbar, and also avoiding the problem of routing clock signals into the crossbar array.
In addition, this implementation can also reduce power. Observe that the longest distance any signal will travel on the horizontal buses is from one side of the small crossbar to the opposite side of the chip. For a 20 mm chip and a 10 mm crossbar centered in the middle of the chip, this distance is 15 mm. On average, signals only travel 7.5 mm; however, the drivers must always charge the entire 20 mm width of the bus. Since the L/S unit will always know if it is sending signals to the left or right, or receiving signals from the left or right, we can break up the bus at each hardwired crosspoint, and only charge up half of the bus. Using this scheme, on average each driver only has to drive 10 mm of wire, which will reduce average power by half.
Although this scheme is also possible with the large crossbar, it would require the signal to pass through two switches instead of one, which impacts delay. Also, each control signal must would have to drive three times as many switches.
4.3
Self Routing CrossbarAnother problem of a single crossbar Figure 4.1 is the need to route control signals to all of the switches. Since the control signals originate in the L/S units, if data is coming from the memory section, and the switch it passes through is also near the memory section, then the data must wait for the control signal to propagate down the height of the crossbar, before the switch is activated. This problem can be alleviated by placing the Load buses close to the vector unit, and the Store buses close to the memory sections, thereby overlapping the control signal propagation time with the data signal propagation time.
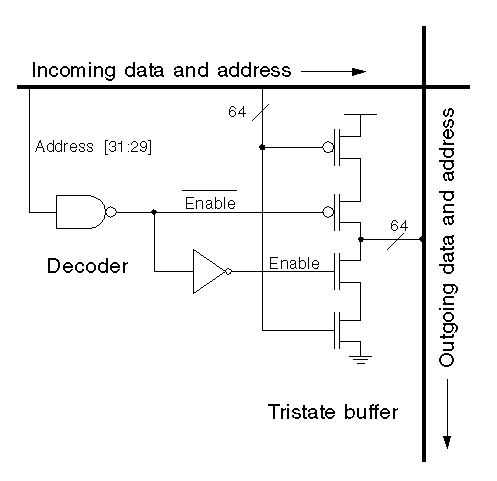
Another approach is illustrated in figure 4.4. In this implementation, the control signals are not routed globally, but instead, are generated locally. This is done at each switch point by decoding the appropriate address bits and if there is a match, activating a tristate buffer which takes the incoming data, arriving on M2, and switches it onto the outgoing M1 line.
Figure 4.4: System diagram for the self routing crossbar. At each switch point, a portion of the address bits are decoded to determine whether the incoming data is driven onto the outgoing line.
This design overcomes several of the problems present in the other designs discussed so far. First of all, the tristate buffer effectively breaks the bus, thereby reducing the overall delay. Although placing buffers at the switch points may not be optimal, the overall delay was still found to improve by several nanoseconds. This is in addition to the fact that the tristate buffer is also providing a "fresh" signal to drive the outgoing bus.
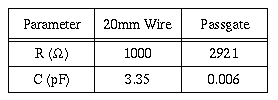
In addition, by using a tristate buffer as the switching element, pass-gates in the signal path can be eliminated. Although the diffusion capacitance of a pass-gate is insignificant when compared to the total capacitance of the bus (table 4.1), the additional resistance is typically three times that of the bus, for minimum size passgates.
Table 4.1: Comparison of the resistance and capacitance of a single 20mm bus wire and a minimum size pass-gate.
This additional resistance increases the RC time constant of the wire by a factor of three over that of the intrinsic wire RC and hence, leads to a significantly longer delay. Typically, buffers are placed near pass-gates to avoid this problem; however, as mentioned previously, the design of this crossbar does not allow for arbitrary placement of buffers.
Finally, since the control for each tristate is generated locally, global control signals and the resulting overhead are not necessary. Moreover, unlike the single large crossbar discussed earlier, the control signal arrives at the switch at the same time as the data signal. Although the data still needs to wait until the control decodes and activates the tristate, this is less than the control delay seen by the large crossbar.
On the other hand, there is also one main disadvantage with this implementation, namely area. This is discussed in the following section.
4.4
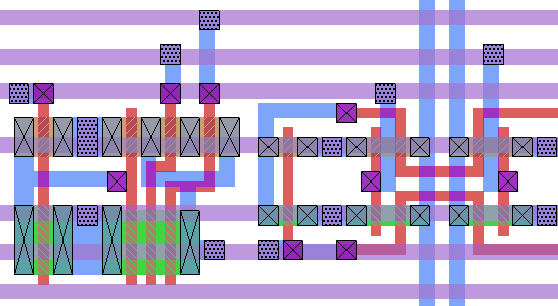
Layout issues for the Crossbar Figure 4.5: A possible layout for the core of the self routing crossbar. Two inverters are shown here, one on the far left and the other on the far right. These inverters flank four tristate buffers, located in the center of the diagram.
The extra area required for the self routing crossbar appears because M2 lines in the core circuit, shown in purple in figure 4.5, cannot be placed at the minimum spacing. In fact, these lines are not address or data lines, but instead, power and ground. Although the sizes of the transistors can be easily increased without impacting the M2 grid, these supply lines cannot be easily rerouted.
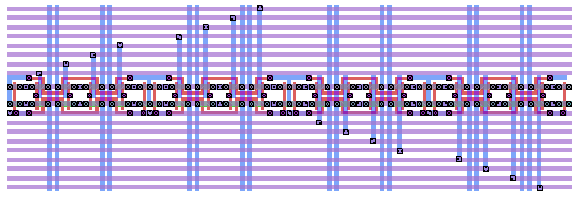
This structure is tiled to create larger arrays as shown below in figure 4.6.
Figure 4.6: A 16x16b self routing crossbar. The incoming data travels on the purple M2 lines and is then switched onto the blue M1 lines by the tristate buffer.
In addition to the tristate buffer, a decoder also needs to be placed within the array. In order to minimize the impact of inserting the decoder, a single three input NAND was inserted, taking care to match the power connections for the decoder to that of the tristate buffers. This is illustrated in figure 4.7. Notice that by routing the supply rails through the center of the array, it is possible to make the NMOS and PMOS as large as necessary without compromising the M2 lines. Moreover, since the decoders fits well into the structure, they can be easily interspersed among the buffers to provide a quicker and more even drive to the tristate buffers.
Figure 4.7: A three input NAND gate with one inverter (left) is shown connected to a tristate buffer (right).
By using a three input NAND gate, a total of eight different locations can be decoded. A single inverter is shown along with the NAND gate in order to generate the complement of one of the address bits; for example, the address "110" requires an inversion on the last bit, the "0," if a NAND gate is to be used as the decoder. As shown in figure 4.7, additional inverters can be easily inserted.
In total, the added complexity of the decoder and tristate buffers was found to increase the overall area of the entire crossbar array by approximately 13%.
Figure 4.8: Four pass-gate switches. Inputs and control enter on M1 at the top. Outputs exit at the bottom in M2. Later they are hardwired to M1 and routed to the bottom of the crossbar. Inputs continue on M1 to the switches on the other horizontal buses.
Transmission gates were used as switches for all the crossbars expect for the self routing implementation. Figure 4.8 shows the layout of four switches in a row. The inputs and control signals for the switch, shown in blue, are routed vertically in M1. The outputs are connected to horizontal purple M2 wires. These run the width of the crossbar, and, at one point, are hardwired to M1 and finally routed to the bottom of the crossbar. Notice that M2 can be routed above the switches thereby making the area cost of a switch zero. The height of the switches is not critical because only n switches need to be placed along a vertical wire. The width of the crossbar is fixed by either the width of the vector unit or the width of the chip; therefore, the area of the crossbar is not sensitive to the size of the switches. However, the number of sections is determined by the size of the switches. Each I/O port from the memory section must be matched with a single pass-gate switch; as a result, the number of I/O ports, and hence the number of memory sections, it constrained by the width of the switches. Assuming that this limit is not reached, then, the crossbar area is only determined by the number of horizontal wires and the minimum spacing between them.
Figure 4.9 shows a 64-bit wide, 4 x 4 crossbar and the path a signal must take from input to output. Inputs enter from the top. If a switch is closed, the signal will be routed horizontally along the metal2 wires, until it hits the hardwired junction, where it proceeds vertically along metal1 wires to the output. If the switch is open, the input signal continues down vertically to the next crosspoint. Exactly one of the switches in a column is closed at once.
Figure 4.9: 64-bit wide 4 x 4 crossbar. Inputs enter at the top and outputs exit at the bottom. The red line shows the path of a data signal. It is routed down until it hits a closed switch, then horizontally until it hits a hardwired junction, and then vertically to the bottom of the crossbar.
4.5 Layout
results| Size of Pass-gate | Self-routing (tri-state buffer) |
|||
|---|---|---|---|---|
| 5x min | 10x min | |||
| # of switches across chip |
8100 | 6600 | 2896 | |
| # of 64-bit buses |
126 | 100 | 45 | |
| # of sections across chip |
2-port | 63 | 50 | 22 |
| 3-port | 42 | 33 | 15 | |
| 5-port | 25 | 20 | 9 | |
| 9-port | 14 | 11 | 5 | |
In order to minimize the height of the crossbar, the total width of the switches need to be matched to the total width of the I/O ports of the memory sections. If the width of the switch is fixed, we can calculate how many sections can fit across the chip without increasing the height of the crossbar. For example, if the width of a single switch is 5 um, 4000 switches can fit across the width of the chip without increasing the height of the crossbar. If each section has three 64-bit ports (2 data and 1 address), then 20 sections can fit across the chip to pitch-match the switches and avoid increasing the height of the crossbar. Table 2 shows how many sections can fit across the chip with different switches, for memory sections with 2-ports (1 data, 1 address), 3-ports (1 Load, 1 Store, 1 address), 5 ports (n=4 data, 1 address), and 9 ports (n load, n store, and 1 address). The 5-port or 9-port sections would be necessary for the small crossbar with the bus, which requires one port per L/S unit.
If we limit the number of sections according to this table, the area of the crossbar will be simply the total width of the buses multiplied by the minimum height. The large crossbar stretches across the entire 20 mm of the chip. It has an area of 2.82 mm2 per 64-bit bus. The small crossbar is only 10 mm wide, but each bus also stretches across the width of the chip so that it has a total area of 4.2 mm2 per 64-bit bus. The self-routing crossbar adds 13% area to the single crossbar since power and ground rails must now be routed horizontally into the crossbar. It has an area of 3.16 mm2 per 64-bit bus.
The area of the low-swing driver was 1000 um2. The area of 64 drivers is only .064 mm2 or 2.2% of the total crossbar area. The size of 64 full-swing inverters that are 32 times minimum size is .015 mm2 or 0.5% of the total area.
4.6 Simulation
Environment Figure 4.10: Critical Path of the Crossbar.
Figure 4.10 shows the critical path through the crossbar. The control signal originates in the vector units and must travel the height of the crossbar to the switch. The data originates in the memory section and must travel horizontally, half the width of the chip plus half the width of the vector unit, and then vertically the height of the crossbar. For four L/S units, 64-bits per bus, and separate address, load data, and store data buses, there are 768 horizontal wires in the crossbar, which gives a height of approximately 2 mm. This gives a height of 768*minimum spacing. For a 20 mm wide chip and a 10 mm wide vector unit, the total horizontal distance is 15 mm.
4.7 Sizing
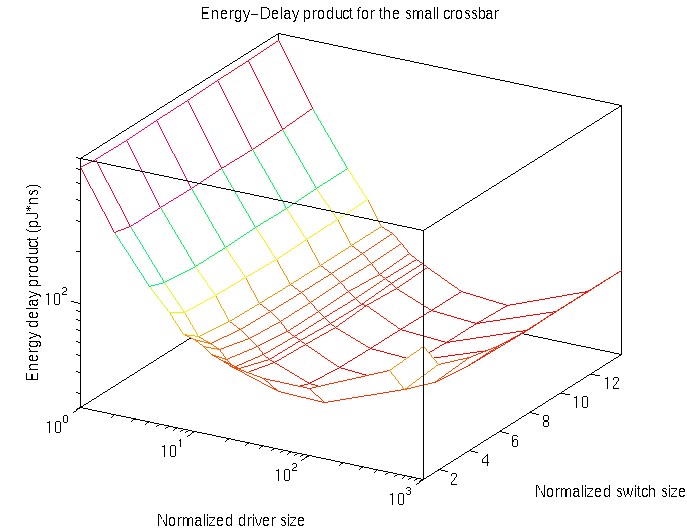
and Energy-Delay productAn often quoted figure of merit is the energy-delay product (EDP). Below, in figure 4.11, is a graph demonstrating the effect on the energy-delay product as the size of the driver and switches are varied. Although the data is given here is for the small crossbar, the shape of the curve is applicable to all the implementations presented in this paper.
Figure 4.11: Simulated energy-delay product for the small crossbar as the driver and switch, or pass-gate, sizes are varied. Each of these sizes are normalized to the minimum size.
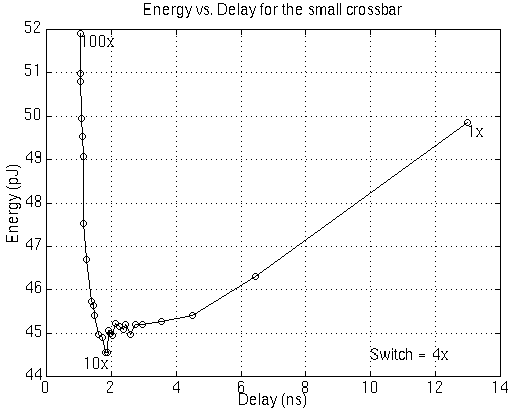
The first thing to notice is that the EDP decreases as the drivers sizes are increased. Although this may seem counterintuitive, as mentioned above, the bus represents a large capacitive load; as a result, the signal transition times are slow for the smaller drivers. This causes the drivers, inverters in this case, to spend extra time in the direct path current regime, thereby increasing the total energy cost. This can be more clearly seen in figure 4.12 which plots the energy vs. delay for a single driver. Notice that increasing the size of the driver from minimum size to approximately 10 times minimum size improves both energy and delay. Beyond this point, the energy increases very quickly for larger drivers due to the extra capacitance of the drivers.
Figure 4.12: Energy vs. Delay for the small crossbar. The driver size to varied from 1x to 100x minimum size while the switch size is fixed at 4x minimum size. The minimum occurs for a driver size of 10x.
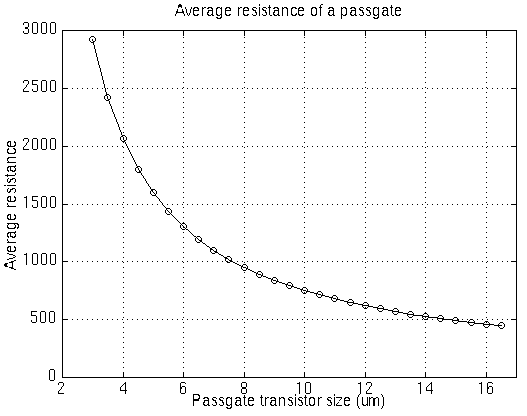
In addition to changing the size of the driver, the delay and energy can also be improved by increasing the size of the pass-gate switch. As mentioned earlier, the additional capacitance of a larger device has a minimum effect on the delay time. The decrease in resistance, on the other hand, is fairly significant. This is shown in figure 4.13.
Figure 4.13: Simulated average resistance of a pass-gate switch , one NMOS and one PMOS, as the size of both the transistors, normalized to a minimum size switch, are varied.
As the pass-gate is enlarged, the resistance decreases. Since the intrinsic resistance of the bus is approximately 1k, sizing the switch for resistances below this value does not significantly improve performance. This effect can be clearly seen in figure 4.11. Notice that the EDP decreases as the pass-gates are sized up from minimum size; beyond this point, however, only small improvements are seen.
In summary, by changing the sizes of the drivers and switches, it is possible to significantly vary the EDP; however, the optimal point may not be a realistic point. From the data presented in figure 4.11, the optimal point, corresponding to an EDP of 35pJ*ns, was found to occur for a driver size of 100 times minimum size. This is clearly not realistic, especially when considering that there could potentially be over 700 of these drivers. On the other hand, by allowing the EDP to double, the driver size falls by a factor of 12.5 to eight times the minimum size.
4.8
Crossbar simulation Results| Large Crossbar | Small Crossbar with bus | Self-Routing Crossbar | |||
|---|---|---|---|---|---|
| Full Swing bus | Low Swing Bus | Full Swing bus | Low Swing Bus | Full Swing | |
| Delay (ns) | 7.9 | 9.5 | 7.7 | 10.0 | 6.0 |
| Energy per Transition (pJ) | 52.0 | 30.7 | 65.2 | 47.2 | 54.3 |
| Static Power (nW) | 1.3 | 65.2 | 2.5 | 17.7 | 5 |
| Energy-Delay Product (10-21 Js) | 411 | 292 | 502 | 472 | 326 |
| Area per 64-bit bus (mm2) | 4.22 | 2.82 | 3.16 | ||
| Driver Area per 64-bits (mm2) | .015 | .064 | .015 | .064 | .015 |
As expected, low-swing drivers reduced the energy per transition considerably. For the single large crossbar, the savings is 70%, while for the small crossbar and bus, the savings is only 38%, since only the bus was implemented with low-swing drivers. The low-swing implementation is only about 20-30% slower, which gives it a much lower EDP.
The combined crossbar and bus consumed more energy than the single crossbar. The implementation of the split horizontal bus could not completely offset the penalty of having two sets of buses. However, this approach may be necessary if the cycle time requires pipelining. The self-routing crossbar was considerably faster than the others, due to the added buffer in the middle of the crossbar. If this area penalty can be kept minimal, having a driver inside the crossbar should be a good alternative.