Figure 2.3.1 - Block Diagram of Encoder
It is useful to be able to guarantee certain characteristics about the information that gets sent across the serial link. These are specific properties that are desirable:
To guarantee these characteristics, an encoder/decoder is used. The encoder takes in incoming data along with some metadata (such as a signal that indicates whether the incoming data represents actual data or control characters) and produces an encoded value which is then transmitted on the link. Similarly, the decoder takes the values from the link and produces the original value, along with some information such as whether the incoming character contains any errors, and whether it represents a data or control character.
After examining some alternatives, the IBM 8B/10B encoding scheme [Wid83] was chosen as the encoding scheme to be used. The IBM 8B/10B encoding scheme exhibits all the desired behaviors. It guarantees a maximum run length of 5 bits; the lowest transition density that can be indefinitely maintained under the encoding scheme is 30 transitions per 100 bits; it can detect all single-bit and many other errors; it contains three different comma characters. The encoding scheme also exhibits some interesting characteristics that are not especially useful in this application. These include the dc-balanced property: the coding scheme generates a bit stream with a balanced number of '1' and '0' bits.
We examined many other encoding schemes. Many schemes address only one of the original concerns. For example, parity or CRCs can guard against single bit errors, but do not provide any synchronization primitives, and do not improve transition density. Furthermore, the error detection in the 8b10b encoding scheme can detect many errors that these do not detect.
It is possible to provide a synchronization sequence that will guarantee that there is at least one transition for every character (for example, appending the sequence "10" to every character). This approach does not improve the transition density beyond adding a single guaranteed transition to every character (although it may add up to three transitions per characters). It is also possible to provide some of the functionality of comma characters using this scheme by using a different sequence, such as "01", to indicate that the character is control. However, this does not truly exhibit all the characteristics of a comma character because it is not singular -- it is not a bit pattern that is not allowed in normal data.
There are two main advantages that some of these other schemes have: first, some of them (such as only using parity) can have a lower overhead. Second, many of them are significantly simpler (and therefore, consume less space). These advantages seem smaller when closely examined. If it is required that multiple additional encoding steps (for example, using parity and appending a synchronization sequence) be used, the first advantage may not exist at all. Also, the simplicity savings may only push the required complexity up to a higher level. The simpler synchronization scheme may require more complex byte synchronization and comma analysis at a higher level.
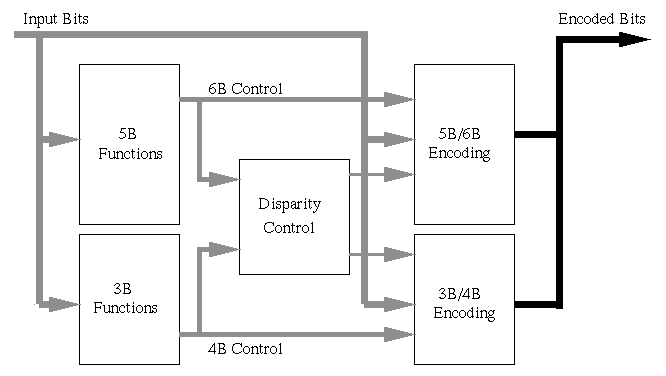
The actual process of encoding works as follows. 8 data bits are presented to the encoder. These data bits are logically separated into two separate categories: the first 5 bits, and the last 3 bits. The first 5 bits are fed into a block (labeled 5B Functions in the block diagram) that produces functions based on the values of those bits. The last 3 bits are likewise fed into a similar block (labeled 3B Functions). These functions are used to determine how the final encoding should occur to maintain DC balancing. The blocks that uses the functions to determine this is labeled Disparity Control in the block diagram. The actual encoding is done in the blocks labeled 5B/6B Encoding and 3B/4B Encoding.
The encoding can be thought of as occuring in two different stages: first, the 5B/6B encoding, then the 3B/4B encoding. Each stage of encoding can produce one of two sorts of outputs: a value of 0 disparity (that is, containing an equal number of '1' and '0' bits), or a value with disparity of +2 or -2 (that is, containing two more '1' bits than '0' bits, or two fewer '1' bits than '0' bits). If a certain input value encodes to a 0-disparity value, that value is generated. Otherwise, either the normal encoding or its complement is generated, based on the current running disparity.
Each 8-bit value that is presented to the encoder is therefore encoded into 2 sub-blocks. These sub-blocks are refered to in the form D.a.b, for data blocks, or K.a.b, for control blocks. In both cases, 'a' represents the value of the value of the 5 bit block to be encoded, and 'b' represents the value of the 3 bit block to be encoded.
The IBM 8B/10B encoding scheme contains pre-defined control characters. These include both comma characters and non-comma characters. The table below shows these values.
| Name | A B C D E F G H | a b c d e i f g h j |
|---|---|---|
| K.28.0 | 0 0 1 1 1 0 0 0 | 0 0 1 1 1 1 0 1 0 0 |
| K.28.1 | 0 0 1 1 1 1 0 0 | 0 0 1 1 1 1 1 0 0 1 |
| K.28.2 | 0 0 1 1 1 0 1 0 | 0 0 1 1 1 1 0 1 0 1 |
| K.28.3 | 0 0 1 1 1 1 1 0 | 0 0 1 1 1 1 0 0 1 1 |
| K.28.4 | 0 0 1 1 1 0 0 1 | 0 0 1 1 1 1 0 0 1 0 |
| K.28.5 | 0 0 1 1 1 1 0 1 | 0 0 1 1 1 1 1 0 1 0 |
| K.28.6 | 0 0 1 1 1 0 1 1 | 0 0 1 1 1 1 0 1 1 0 |
| K.28.7 | 0 0 1 1 1 1 1 1 | 0 0 1 1 1 1 1 0 0 0 |
| K.23.7 | 1 1 1 0 1 1 1 1 | 1 1 1 0 1 0 1 0 0 0 |
| K.27.7 | 1 1 0 1 1 1 1 1 | 1 1 0 1 1 0 1 0 0 0 |
| K.29.7 | 1 0 1 1 1 1 1 1 | 1 0 1 1 1 0 1 0 0 0 |
| K.30.7 | 0 1 1 1 1 1 1 1 | 0 1 1 1 1 0 1 0 0 0 |
The actual process of encoding works as follows. 8 data bits are presented to the encoder. These data bits are logically separated into two separate categories: the first 5 bits, and the last 3 bits. The first 5 bits are fed into a block (labeled 5B Functions in the block diagram) that produces functions based on the values of those bits. The last 3 bits are likewise fed into a similar block (labeled 3B Functions). These functions are used to determine how the final encoding should occur to maintain DC balancing. The blocks that uses the functions to determine this is labeled Disparity Control in the block diagram. The actual encoding is done in the blocks labeled 5B/6B Encoding and 3B/4B Encoding.
The encoder is approximately 280x230 microns, and the decoder is approximately the same size. Simulation of the functional blocks in the encoder and decoder show that the power consumption in typical operation for both the encoder and decoder is less than a milliwatt.